完整链接:https://rpubs.com/SiQingYe/751255
资料处理流程
- 资料前处理
- 简单的Feature Engineering
- 只保留Cabin的舱位号(前面的字母)。
- 把Name中的有一定含义的 title 元素提取出来,并将比较少用的title合并到比较常用的tittle中,建立一个新的类别“Title”
- 把姓氏提取出来,创建新的类别“Surname”
- Missing Data
- NA值 & 空白值
- 减少资料量
- 属性的筛选:删掉不要的属性
- 正规化处理
- 简单的Feature Engineering
- 模型的建立
- 随机森林(Random Forest)
- SVM(Support Vector Machines)
- GBM(Gradient Boosting Machine)
- 模型的解释
- 预测及分析
- 混淆矩阵
- ROC
- AUC
资料前处理
简单的Feature Engineering:
- 只保留Cabin的舱位号(前面的字母)。
- 把Name中的有一定含义的 title 元素提取出来,并将比较少用的title合并到比较常用的tittle中,建立一个新的类别“Title”
- 把姓氏提取出来,创建新的类别“Surname”

Missing data:
NA值主要来自Age和Cabin(Survived的缺失值,是test中填补的NA)

方法:这边我们选择用mice填补Age和Fare的缺失值
查看填补之后的结果:
空值:只来自Embarked

查看Embarked的类别及各个类别的资料笔数,选择资料笔数最的类别(“S”)填补填补到Embarked的空值中
减少资料量:
属性的筛选:删掉不要的属性
- Name & Surname:类别太多了,并且没有什么特别的用途。
- Ticket:里面都是一些随机的数字,没有特多含义,并且是多值属性不好处理。
- Cabin:有太多的NA值,并且为类别变数不好填充,如果给一个Ncabin的类别,会使得属性非常unbalance。
- PassengerId:只是一个序列号,没有太多的含义。

Data 正规化:
数值变量的range没有特别的大,所以没有做特别的正规化处理
模型的建立
因为test 资料集中没有“Survuved”栏位,所以我们从train资料集中分出30%作为验证集。
剩下的train中的70%资料用于训练模型,训练中也会做cross-validation。
下面建立了三个模型:
- 随机森林(Random Forest)
- SVM(Support Vector Machines)
- GBM(Gradient Boosting Machine)
- ⚠️ KNN一般可以作为分类的baseline
随机森林:
1 | # 随机森林 |

我们可以看出选择出的最好的模型是mtry = 3的时候。
SVM:
1 | # SVM |
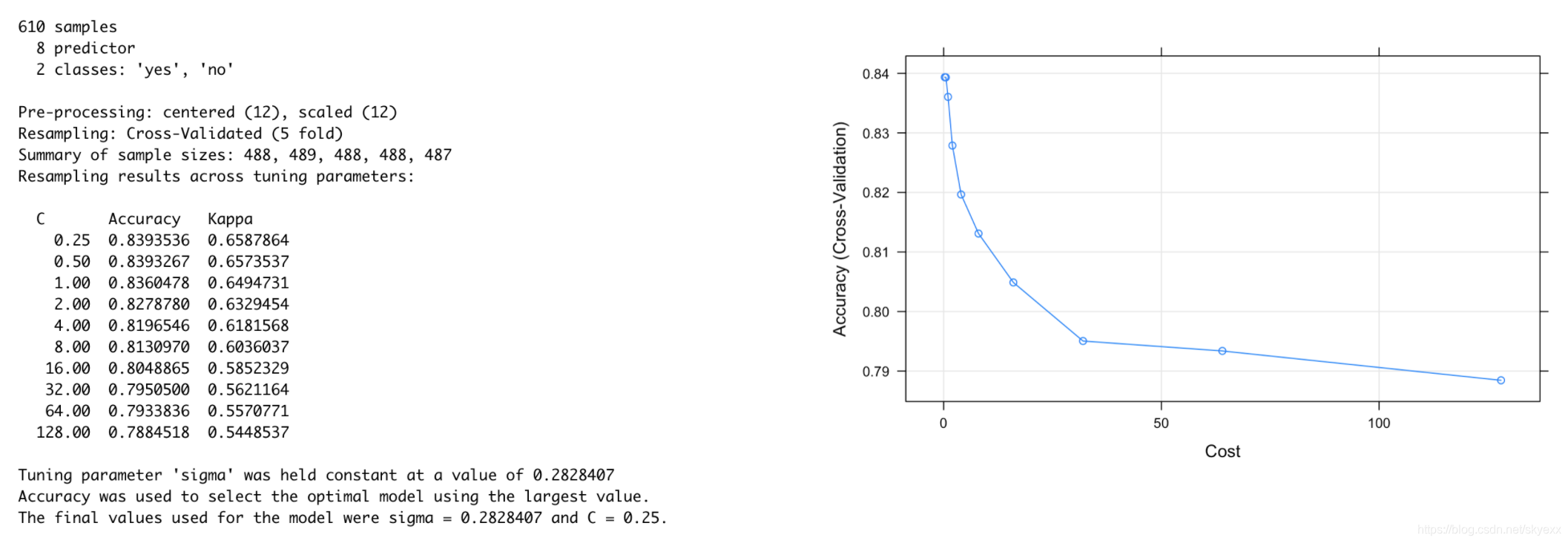
我们可以看出最好的模型是 sigma=0.2828,C=0.25的时候。
GBM:
1 | # (GBM) model |

我们可以看出GBM选出的最好的模型是n.trees=200,且深度为3 interaction.depth = 3的模型。
模型的解释
这里直接利用library("DALEX")包的解释函数对三个模型进行解释性分析
累积残差分布:

由上图我们可以看,绿色的线在最上方,也就是SVM中大部分的样本残差都比较大。而红色的线是RF模型,它的大部分的样本残差都比较小。可以看出树的模型的残差线对于SVM这类的模型都要来的比较小一些。
变数重要性分析:

可以看出三个模型中的变数重要性的排序基本上是一样的。
测试训练好的模型并分析结果
我们用之前从train的资料集中分出的valid资料来做各个模型的测试
1 | # 使用不同的已经训练好的模型分类预测: |
预测出来的结果(这边仅以Random Forrest的处理过程为例):
如图:
1 | # 查看训练集的预测情形 |
我们将是否存活的机率的门槛设置为0.5,我们可以看到计算出来的准确率为:0.6981132
我们想了解不同门槛值的预测情况,所以就先粗略切了[0,0.5,0.55,0.6,0.65,0.7,0.8,1]这些区间来看看,是否有更好的门槛值设定。
1 | # 查看测试集分类机率在不同门槛值下的预测情况 |
根据下表的分布情况似乎切在0.8左右会更好
混淆矩阵 :
那么我将预测结果依照分类机率大于0.8当成1来建立混淆矩阵,并对三个模型都建立了混淆矩阵来进行对比: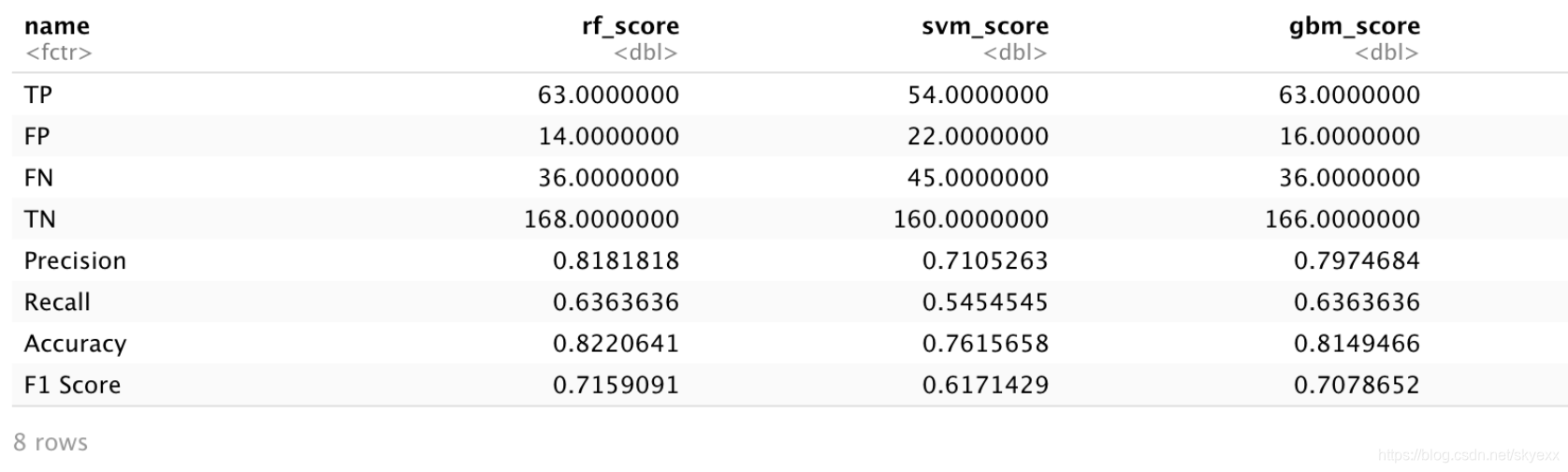
可以看出三个模型:
预测的准确率(Accuracy)以及F1 Score 最高的都是 Random Forrest
三个模型主要犯的都是FN(false negative)的错误,既将实际存活的人判断为了死亡。
同时我们可以看到SVM在准确率(Accuracy)上和其他两个模型相差的并不多,但是 F1 Score 的分数就要比其他两个模型低很多。
Accuracy = (TP+TN)/(TP+FP+FN+TN)
Recall = TP/(TP+FN)
Precision = TP/(TP+FP)
F1-score = 2 * Precision * Recall / (Precision + Recall)
那么我们可以根据F1-score 的公式看出他是Precision和Recall两者调和平均,而Precision和Recall两者可以比较好的度量分类错误的情况。所以我们可以推测出SVM的模型对于FP和FN的判断不是很好,但对于TP和TN的预测效果还是可以的。
ROC:
上面的混淆矩阵我是透过比较粗糙的方式切出的 0.8 作为门槛来进行三个模型的比较的。
但是想进一步比较三个模型效果还是应该来看一个更为细致的ROC曲线和AUC的值。
红线为:Random Forest
- 最佳的切分值:0.835 or 0.737
绿线为:SVM
- 最佳的切分值:0.808 or 0.798
蓝线为:GBM
- 最佳的切分值:0.885 or 0.717

在ROC的图中越是靠近左上角的部分他的TPR越大而FPR越小,也就是模型的效果就越好。可以看出蓝线和红线都完全包裹在绿线的外面,所以我们可以认为Random Forest和GBM做为这个资料集的分类器效果都比SVM更好。而Random Forest和GBM的比较我们我们只从ROC不能看出哪一个模型比较好,所以我们需要进一步分析两个模型的AUC值。
AUC:
AUC也就是ROC曲线下方的面积,AUC值越大的分类器,正确率越高。
根据 AUC 比较模型的效果也就是:Random Forest(0.844) > GBM(0.836) > SVM(0.795)